Semantische Metadaten für den Webauftritt einer Bibliothek
Andreas Bohne-Lang 11 Medizinische Fakultät Mannheim, Universität Heidelberg, Mannheim, Deutschland
Zusammenfassung
Das Semantic Web ist schon seit über 10 Jahren viel beachtet und hat mit der Verfügbarkeit von Resource Description Framework (RDF) und den entsprechenden Ontologien einen großen Sprung in die Praxis gemacht. Vertreter kleiner Bibliotheken und Bibliothekare mit geringer Technik-Affinität stehen aber im Alltag vor großen Hürden, z.B. bei der Frage, wie man diese Technik konkret in den eigenen Webauftritt einbinden kann: man kommt sich vor wie Don Quijote, der versucht die Windmühlen zu bezwingen. RDF mit seinen Ontologien ist fast unverständlich komplex für Nicht-Informatiker und somit für den praktischen Einsatz auf Bibliotheksseiten in der Breite nicht direkt zu gebrauchen. Mit Schema.org wurde ursprünglich von den drei größten Suchmaschinen der Welt Google, Bing und Yahoo eine einfach und effektive semantische Beschreibung von Entitäten entwickelt. Aktuell wird Schema.org durch Google, Microsoft, Yahoo und Yandex weiter gesponsert und von vielen weiteren Suchmaschinen verstanden. Vor diesem Hintergrund hat die Bibliothek der Medizinischen Fakultät Mannheim auf ihrer Homepage (http://www.umm.uni-heidelberg.de/bibl/) verschiedene maschinenlesbare semantische Metadaten eingebettet. Sehr interessant und zukunftsweisend ist die neueste Entwicklung von Schema.org, bei der man eine ‚Library‘ (https://schema.org/Library) mit Öffnungszeiten und vielem mehr modellieren kann. Ferner haben wir noch semantische Metadaten im Open Graph- und Dublin Core-Format eingebettet, um alte Standards und Facebook-konforme Informationen maschinenlesbar zur Verfügung zu stellen.
Schlüsselwörter
Web-Technologie, Semantic Web, Metadaten, Schema.org, Bibliothek
Einleitung
Das World Wide Web wird auch als WWW, W3 oder Web abgekürzt. Häufig wird auch der Begriff ‚Internet‘ als Synonym verwendet, was nicht korrekt ist, da das WWW nur ein Teil dessen ist, was das Internet ausmacht. Eine der großen Herausforderungen des Word Wide Web der Gegenwart ist es, die bereitgestellten Informationen so aufzubereiten, dass diese präzise bei einer Websuche gefunden werden können.
Informationen im WWW werden auf Webseiten (Web Pages) zur Verfügung gestellt, die in der Regel im Dateiformat html erstellt sind. Die Gesamtheit der Webseiten eines Webauftritts (z.B. einer Bibliothek) wird als Website bezeichnet, da sie zusammen an einem Speicherort unter einer logischen URL (uniform resource locator, symbolische Web-Adresse) bzw. einer physischen Adresse (IP-Nummer) abgelegt sind. Die ähnlich klingenden Begriffe „Website“ und „Webseite“ bezeichnen also verschiedene Sachverhalte und dürfen nicht verwechselt oder gar synonym benutzt werden.
Suchmaschinen und deren Betreiber spielen eine federführende Rolle bei der Suche von Information anhand von Suchvorgaben im Web; denn sie bestimmen die auf eine Anfrage gefundenen Suchtreffer und somit die Sichtbarkeit potentieller Funde im Web. Derzeit ist der Suchraum von Suchmaschinen eingeschränkt, da diese nur die Webseiten-Inhalte indexieren und in der Regel keine Information über deren Bedeutung haben. Komplexe Kontextinformationen über den Inhalt einer Webseite werden von den Webseiten-Erstellern meist nicht zur Verfügung gestellt. Suchanfragen von Benutzern basieren bei den großen Suchmaschinen für gewöhnlich auf einzelnen Stichworten, welche mit einem logischen ‚und‘ verknüpft werden. Anfragen komplexerer semantischer Natur wie ‚Welche Bibliothek im Umkreis hat heute bis 20 Uhr geöffnet und hat das Buch „Anatomische Prüfungsfragen“‘ sind derzeit nicht möglich. Einer der Gründe hierfür ist die fehlende semantische Kodierung der Inhalte der Webseite in Form von Metadaten innerhalb ihrer html-Datei, so dass diese maschinenlesbar und bedeutungstragend hinterlegt wären. Dieser Artikel soll kurz beschreiben, wie (Medizin-)Bibliotheken, Arztpraxen, Krankenhäuser und andere Webseitenbetreiber hier selber aktiv eingreifen und somit semantische Inhalte auf ihrem Webauftritt verankern können, um zukünftig komplexe Suchanfragen zu fördern und zu ermöglichen.
Metadaten in Bibliotheken
Bei der Definition von Metadaten in Bibliotheken sei hier die Deutsche Nationalbibliothek zitiert, welche auf ihrer Website folgendes schreibt: „Metadaten sind (strukturierte) Daten, die eine Ressource, eine Entität, ein Objekt oder andere Daten beschreiben. Sie können darüber hinaus dem Auffinden, der Verwendung sowie der Verwaltung einer Ressource, einer Entität etc. dienen. Der Begriff Metadaten wird in unterschiedlichen Kontexten verwendet. Im informationswissenschaftlichen und bibliothekarischen Kontext versteht man hierunter Daten, die der Beschreibung von elektronischen Ressourcen dienen. Der Trend geht jedoch dahin, den Begriff Metadaten auch für Daten und Kataloge in Datenbanken zu verwenden, die nicht-elektronische Ressourcen beschreiben.“ [1]. In Bibliotheken ist die Erfassung von Metadaten von Medien schon seit jeher eines der Hauptaufgabengebiete des Erwerbungsprozesses. Dabei unterscheidet man in der Erschließung zwei Teilbereiche: Die Formalerschließung und die Sacherschließung. Die Formalerschließung erfasst die bibliographische Beschreibung des Werkes wie Name des Autors, Erscheinungsjahr, Erscheinungsort und Verlag, aber auch Seitenanzahl, Größe und Kaufpreis. Dabei hält sich die Formalerschließung eng an bibliothekarische Regelwerke, um einen Austausch der Daten mit anderen Einrichtungen zu ermöglichen. Die aktuellen Regelwerke sind Regeln für die alphabetische Katalogisierung (RAK) und Resource Description and Access (RDA). Im Gegensatz zu der Formalerschließung steht die Sacherschließung oder auch Inhaltserschließung. Hierzu wird der Inhalt des Mediums per Autopsie von einer geschulten Person wie z.B. einem Fachreferent erfasst und klassifiziert. Bei der Klassifikation wird das Medium bestimmten semantischen Kategorien eines meist hierarchischen Ordnungssystems zugeordnet. Als bekannteste und gebräuchlichste sind die Dewey Decimal Classification (DDC), die Regensburger Verbundklassifikation (RVK) und die Library of Congress Classification (LCC) zu nennen. Aber auch Klassifikationen von Verlagen und dem Buchhandel wie ONline Information eXchange (ONYX) oder Business Industry Classification (BIC) werden verwendet.
Allen Metadaten gemein ist, dass sie das Auffinden von Medien bzw. Medieninhalten erleichtern und ermöglichen sollen. Betrachtet man die Aufstellungssystematik ‚numerus currens‘ (fortlaufende Nummer) in Bibliotheken, bei der die Medien in der zeitlichen Abfolge der Erwerbung in die Regale gestellt werden (was konkret einer zufälligen Aufstellung entspricht), so bedarf das Auffinden einzelner Medien umfangreiche Kenntnisse über das Werk. Dabei stammen die Ansätze und Lösungen zum Auffinden aus Zeiten ohne Computer und Suchmaschinen und konnten nur mit Mitteln der lokalen Bibliothek umgesetzt werden.
Semiotisches Dreieck
Das Semiotische Dreieck (siehe Abbildung 1 [Abb. 1]) beschreibt das Problem, welches die Verarbeitung von Informationen mit sich bringt. Dieses lässt sich in drei Teilbereiche aufteilen:
Abbildung 1: Semiotisches Dreieck 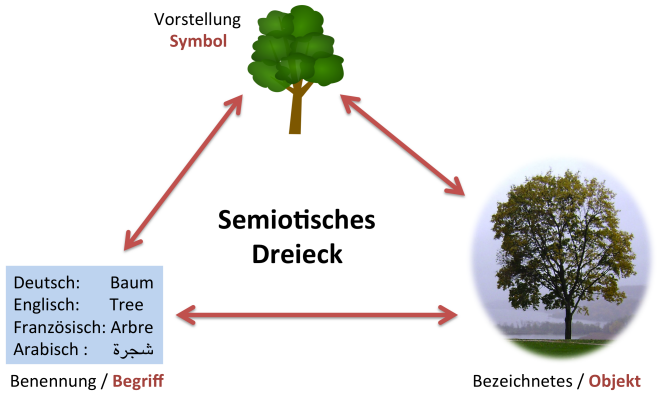
- Zum einen gibt es in unserer Vorstellung die (abstrakte) Idee eines Objektes. Wenn wir uns einen Baum vorstellen, so assozieren wir Gedanken wie: „oben Zweige, unten Wurzeln, betreibt Photosynthese, benötigt Wasser, ist im Sommer grün, der Stamm ist aus Holz“, etc. Dass alles zusammen bildet die Idee eines Baumes.
- Dann gibt es die konkrete Ausprägung (das Objekt) dessen, worauf sich unsere Vorstellung beruft, also einen echten Baum in der Landschaft wie eine Eiche, Fichte oder einen Apfelbaum.
- Der dritte Teil des Semiotischen Dreiecks ist die Benennung. Durch die Sprachvielfalt hat jede Sprache ihren eigenen Ausdruck für ‚Baum’. Die Engländer bezeichen es als ‚tree’, die Franzosen als ‚arbre’ und im Arabischen ist es ‚
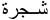 ’.
’.
Bei der maschinellen Verarbeitung von Daten muss man die drei Teilbereiche berücksichtigen. Neben der eigentlich Information muss man Daten über die Information bereit halten. So ist z.B. die Zahl 45678 zunächst nur eine Zahl ohne Bedeutung. Erst mit der Zuordnung einer Verwendung, wie „Telefonnummer=45678“, wird der Kontext festgelegt, in dem diese Zahl Anwendung findet. Die gleiche Zahl kann in einem anderen Kontext eine andere Bedeutung haben. Daher bedarf es bei der Verarbeitung von Informationen semantischer Angaben darüber, in welchem Kontext die Daten anzuwenden sind. Wichtig ist in diesem Zusammenhang, dass man ein gemeinsames Wörterbuch mit Schlüsseln definiert und diese eindeutig festlegt. Die Verwendung verschiedener Schlüssel (Systeme) erschwert oder verhindert die maschinelle Verarbeitung, da man auf Konkordanzen angewiesen wäre. Für die maschinelle Verarbeitung muss das Wissen ferner strukturiert abgebildet werden. Hierfür gibt es verschiedene Möglichkeiten mit unterschiedlicher Mächtigkeit. Neben dem reinen Festlegen von Begriffen gibt es die Möglichkeiten, Über- und Unterordnungen, Wenn-Dann-Beziehungen, Begriffs-Räume, Synonyme und Ähnlichkeiten etc. zu definieren.
Im Bereich der Wissensrepräsentation kann man die semantische Reichhaltigkeit nach Pellegrini und Blumauer [2] in ihrer Mächtigkeit bewerten:
Semantische Reichhaltigkeit
- Glossar: Ist eine einfache, meist alphabetisch sortierte Liste von Wörtern und ihren Erklärungen.
- Folksonomy: Ist ein Kofferwort, das sich aus Folk und Taxonomie zusammensetzt. Es beschreibt von Benutzern (folks) vergebene Schlagworte (Tags) zu einem Begriff und entspringt dem Web 2.0-Umfeld.
- Taxonomie: Die Taxonomie ist ein hierarchisches System, das mit dem Bildungsprinzip Über-/Unterordnung Elemente strukturiert. Taxonomien spielen z.B. in der Biologie mit der Unterteilung der Lebewesen in Art, Gattung oder Familie eine bedeutende Rolle.
- Thesaurus: Der Thesaurus erweitert die Taxonomie um die zwei fest definierten Relationen der Objekte untereinander: die Ähnlichkeits- und die Synonym-Relation.
- Topic Map: Sie besteht aus abstrakten Dingen, Assoziationen, Gültigkeitsbereichen für abstrakte Dinge und zugeordneten Dokumenten außerhalb der Topic Map. Es lassen sich Assoziationen zwischen den Objekten selbst definieren.
- Ontologie: Die Königsdisziplin – sie besteht aus Begriffen, Typen, Instanzen, Relationen, Vererbung und Axiomen, welche Zusammenhänge zwischen den einzelnen Objekten der Ontologie als auch mit anderen Ontologien mittels „wenn-dann“-Beziehungen, Zuweisungen, logischen Verknüpfungen und weiteren Funktionen ausdrücken kann.
Austausch von Informationen im Computerzeitalter
Nachdem ab den 80er Jahren immer mehr Rechner von großen Einrichtungen über fest definierte Adressen, Schnittstellen und Protokolle miteinander vernetzt wurden, entstand das „Internet“. Das World Wide Web im engeren Sinne entstand 1989 als Projekt an der Forschungseinrichtung CERN und wurde von Tim Berners-Lee entwickelt. Dazu programmierte er einen Server und einen Client, der in der Lage war, Hypertexte, also Texte mit Verweisungen auf andere Adressen, zu verarbeiten. Am 6. August 1991 veröffentlichte er das ‚World Wide Web-Projekt‘ in einem Beitrag zur Newsgroup alt.hypertext und lud dazu ein, diese Software zu benutzen [3].
Das zugrunde liegende Hypertext Transfer Protocol (HTTP) war als offener Standard konzipiert und hat bis heute Bestand. Seit dieser Zeit spielt Tim Berners-Lee eine maßgebliche Rolle bei der Weiterentwicklung des World Wide Web, da er 2004 das World Wide Web Consortium (W3C) gründete, diesem als Direktor vorsteht und Standards, Spezifikationen, Richtlinien, Software und Hilfsprogramme (Tools) (mit-)entwickelt.
Metadaten in Webseiten
Für die Kennzeichnung von Metadaten innerhalb von Webseiten griff Berners-Lee auf das Konzept der Auszeichnungssprachen (Markup Languages) zurück, das schon in Form der Standard Generalized Markup Language (SGML) bekannt war. Bereits im ersten Entwurf von 1993 „Hypertext Markup Language (HTML) – A Representation of Textual Information and Meta Information for Retrieval and Interchange“ [4] sah Tim Berners-Lee vor, dass Webseiten einen Kopfbereich
haben, in dem Metadaten über die Webseite untergebracht werden sollen, und einen Inhaltsbereich . Der damalige Entwurf definierte im Kopfbereich nur die TagsLiteratur
[1] Deutsche Nationalbibliothek. Metadaten. 2016. Available from: http://www.dnb.de/DE/Standardisierung/Metadaten/metadaten_node.html[2] Pellegrini T, Blumauer A. Semantic Web und semantische Technologien: Zentrale Begriffe und Unterscheidungen. In: Pellegrini T, Blumauer A, editors. Semantic Web – Wege zur vernetzten Wissensgesellschaft. Berlin Heidelberg: Springer; 2006. p. 9-25.
[3] Berners-Lee T. WorldWideWeb: Summary. 1991. Available from: http://groups.google.com/forum/#!msg/alt.hypertext/eCTkkOoWTAY/bJGhZyooXzkJ
[4] Berners-Lee T, Connolly D. Hypertext Markup Language (HTML). A Representation of Textual Information and MetaInformation for Retrieval and Interchange. 1993. Available from: https://www.w3.org/MarkUp/draft-ietf-iiir-html-01
[5] Berners-Lee T, Connolly D. Hypertext Markup Language – 2.0. 1995. Available from: https://tools.ietf.org/html/rfc1866
[6] Raggett D. HyperText Markup Language Specification Version 3.0. 1995. Available from: https://www.w3.org/MarkUp/html3/html3.txt
[7] Arnett N, Bowman M, Christian E, Connolly D, Koster M, John K, Lagoze C, Mauldin M, Mogensen C, Nichols W, Niesen T, Weibel S, Wood A. A Proposed Convention for Embedding Metadata in HTML. 1996. Available from: https://www.w3.org/Search/9605-Indexing-Workshop/ReportOutcomes/S6Group2
[8] Johnston P, Powell A. Expressing Dublin Core metadata using HTML/XHTML meta and link elements. 2008. Available from: http://dublincore.org/documents/2008/08/04/dc-html/
[9] Suchoperatoren – Google Websuche-Hilfe. 2016. Available from: https://support.google.com/websearch/answer/2466433?hl=de
[10] Berners-Lee T, Hendler J. Publishing on the semantic web. Nature. 2001 Apr;410(6832):1023-4. DOI: 10.1038/35074206
[11] Berners-Lee T, Hendler J, Lassila O. The Semantic Web. Scientific American. 2001;284(5):34-43. DOI: 10.1038/scientificamerican0501-34
[12] Berners-Lee T. Linked Data – Design Issues. 2006 [updated 18.06.2009]. Available from: https://www.w3.org/DesignIssues/LinkedData.html
[13] Linked Open Vocabularies (LOV). 2016. Available from: https://lov.okfn.org/dataset/lov/
[14] D’Arcus B, Giasson F. Bibliographic Ontology Specification – The Bibliographic Ontology. 2009. Available from: http://purl.org/ontology/bibo/
[15] Shotton D, Peroni S. FaBiO, the FRBR-aligned Bibliographic Ontology. 2016. Available from: http://purl.org/spar/fabio/
[16] Voß J. The Service Ontology. 2013. Available from: http://purl.org/ontology/service
[17] Klee C, Jakob V. Holding Ontology. 2015. Available from: http://purl.org/ontology/holding
[18] Voß J. Document Service Ontology (DSO). 2013. Available from: http://purl.org/ontology/dso
[19] Danowski P, Pohl A, editors. (Open) Linked Data in Bibliotheken. Berlin, Boston: de Gruyter, Saur; 2013. DOI: 10.1515/9783110278736
[20] Hepp M, editor. An Ontology for Describing Products and Services Offers on the Web. 16th International Conference on Knowledge Engineering and Knowledge Management (EKAW2008). Acitrezza, Italy: Springer LNCS; 2008.
[21] Cookbook – GoodRelations Wiki 2016 [The GoodRelations Cookbook is a growing collection of recipes for developers]. Available from: http://wiki.goodrelations-vocabulary.org/Cookbook
[22] GoodRelations Snippet Generator 2016. Available from: http://www.ebusiness-unibw.org/tools/grsnippetgen/
[23] Full Hierarchy – schema.org 2016. Available from: http://schema.org/docs/full.html
[24] Google Test-Tool für strukturierte Daten. 2016. Available from: https://search.google.com/structured-data/testing-tool
[25] Official Google Webmaster Central Blog: Google does not use the keywords meta tag in web ranking. 2009. Available from: https://webmasters.googleblog.com/2009/09/google-does-not-use-keywords-meta-tag.html
[26] Edwards C. Is The Meta Keyword Tag Used By Google, Bing or Yahoo? 2014. Available from: https://chrisedwards.me/seo/keyword-meta-tag-google/
[27] Meta-Tags, die Google versteht – Search Console-Hilfe. 2016. Available from: https://support.google.com/webmasters/answer/79812?hl=de
[28] MedicalWebPage – health-lifesci.schema.org. 2016. Available from: https://health-lifesci.schema.org/MedicalWebPage
[29] Bohne-Lang A. Semantische Daten für den Webauftritt einer Bibliothek. In: Arbeitsgemeinschaft für medizinisches Bibliothekswesen (AGMB). Jahrestagung der Arbeitsgemeinschaft für medizinisches Bibliothekswesen (AGMB). Göttingen, 26.-28.09.2016. Düsseldorf: German Medical Science GMS Publishing House; 2016. Doc16agmb01. DOI: 10.3205/16agmb01
[30] Dublin Core Metadata Element Set, Version 1.0: Reference Description. 1998. Available from: http://dublincore.org/documents/1998/09/dces/

